



Tabla de contenidos
¿Alguna vez has querido extraer texto que estaba dentro de un archivo PDF protegido o de una imagen y te ha sido imposible? Pues ahora puedes extraer ese texto fácilmente gracias a Google ¡como no!
Google ha creado una maravillosa herramienta de Reconocimiento Óptico de Caracteres (OCR) que te permite extraer texto de cualquier imagen y de cualquier archivo PDF. Lo mejor es que es gratuita y está disponible para más de 250 idiomas de todo el mundo.
Cómo extraer texto con la herramienta OCR de Google drive
Lo primero que debes saber es que Google Drive soporta los siguientes formatos de archivo: JPEG, GIF, PNG y por supuesto PDF.
¡Paso a paso!
- Entra en Google Drive
- Haz click derecho y sube la imagen o el archivo PDF al servidor de Google Drive. En nuestro ejemplo subimos una imagen llamada insertando_texto.gif

- Una vez subido el archivo de imagen o PDF que quieras convertir, haz nuevamente click derecho sobre él y a continuación, haz click en Abrir con -> Documentos de Google.
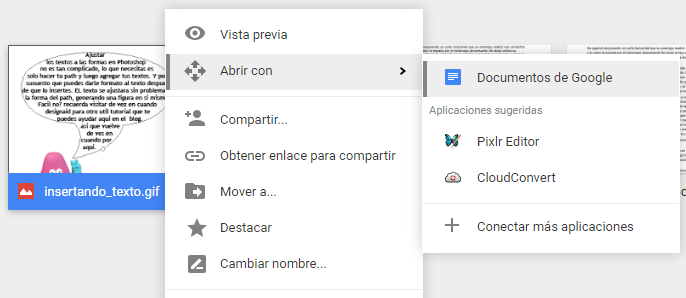
- Esperas unos segundos… y tendrás convertida la imagen a un documento de Google. En esos segundos ha actuado el software de reconocimiento óptico de caracateres. Ahora el texto extraído de la imagen es perfectamente copiable y editable.
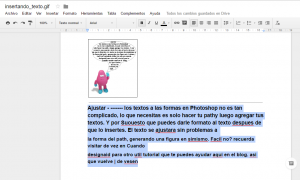
Si haces click sobre la imagen de arriba, podrás observar el resultado directamente en Documentos de Google. Como ves, el texto contiene pequeños errores, ¡solo hay que poner manos a la obra para arreglarlo y listo!
Para que el texto resultante contenga menos fallos, ten en cuenta estos simples consejos:
- Las imágenes deben ser lo más nítidas posible; si son fotos borrosas el resultado contendrá más errores.
- La altura de la letra debe ser de 10 píxeles de alto (como mínimo)
- Los archivos tanto de imágenes como PDF, deben tener un tamaño máximo de 2 MB.
- Ubica la imagen correctamente ¡no la pongas patas abajo!
- Las fuentes mejor detectadas son la Times New Roman o la Arial.
- El formato (tablas, negritas, etc.) se mantendrá en la medida en que la imagen sea más o menos clara.
Esto es todo por hoy, como has podido ver, se terminaron los PDF protegidos y las imágenes con textos imposibles de extraer.
Espero que te haya sido útil el tutorial y que lo compartas con tus amigos 
¡Salud y OCR para todo el mundo!